An Actually Correct Explanation of P-Values
It's become a running joke that nobody understands p-values. 46% of Ob-Gyn doctors incorrectly answer a simple question about what p-values are. 89% of "Introduction to Psychology" textbooks that cover statistical significance do so incorrectly. When some doctors did a survey of medical residents to see how many of them understood p-values, none of the possible answers on the survey were correct. FiveThirtyEight writes about how not even scientists can easily explain p-values. While writing this article, I Googled "an intuitive explanation of p-values" and read the first 20 results. 16 of them contained statistical errors.

I recognize the danger of trying to write my own guide. Many of the p-value explanations referenced above did something very similar; start by saying that p-values are often misunderstood, claim they're providing a better answer, then make a bunch of embarrassing mistakes. The risk of me doing the same is, to some extent, unavoidable, but I've done my best. If you notice any mistakes or omissions, please contact me. Given this, and in accordance with Cunningham's Law I will now state that this is the definitive introduction to p-values.
So what is a p-value? The technical definition:
The p-value of a study is an approximation of the a priori probability that the study would get results at least as confirmatory of the alternative hypothesis as the results they actually got, conditional on the null hypothesis being true and there being no methodological issues in the study.
"A priori" means that we're looking at the probability that would have been calculated before the study took place. (After the study is conducted, the probability is always 100%; those results were in fact gotten!) "Null hypothesis" refers to the hypothesis that whatever effect being tested for doesn't exist. For example if you want to know whether a certain drug cures malaria, the null hypothesis would be "this drug has no effect on malaria". The alternative hypothesis is the one that they're testing for, like "this drug does cure malaria". And "confirmatory results" are any results that would indicate your alternative hypothesis is true. If you're testing to see whether a drug cures malaria, an example confirmatory result would be that 95% of people you give the drug to are cured within a day.
So in other words, if we assume that whatever effect is being tested for doesn't exist, the p-value is a rough measure of the chance that you'd get results that look at least this promising just due to random chance.
Or in even simpler terms, the p-value is a measure of how surprised you should be by seeing these results, if you thought that the effect being tested for didn't exist.
Let's break that down a little more.
Conditional probability
Imagine you've built a die-rolling machine, and you want to get a 5. You have two dice available to you: a d6 and a d20. Which should you put in the machine?
To make your decision, you'd want to consider what the probability would be of getting a 5 if you made either choice. If you were to choose the d6, your chance of rolling a 5 is 1/6. This is the conditional probability of rolling a 5, conditional on choosing the d6. The probability of rolling a 5 conditional on choosing the d20 is only 1/20, which is lower than 1/6, so you should choose the d6.
(There's also some unconditional probability of rolling a 5, which depends on all of your knowledge about the situation. For example if you know that your friend has already loaded a die into the machine and flipped a coin in order to decide which die to put in, then the unconditional chance of rolling a 5 would be (1/6 * 1/2) + (1/20 * 1/2).)
The unconditional probability of a certain event is generally written as P(event), and the conditional probability as P(event|condition). The "|" symbol can be read as "conditional on" or "given", so P(falling|climbing the ladder) means "the chance of falling conditional on climbing the ladder". If you don't climb the ladder, the chance would be lower.
The most important thing to understand about conditional probability is that P(A|B) does not necessarily equal P(B|A). If all you know about Alice is that she went swimming, what's the chance that she got wet? Extremely high! But if all you know about Alice is that she got wet, what's the chance she went swimming? Much lower; it could have been rain, or a sprinkler, or taking a shower, or any number of other causes.
This is one of the most common errors made with regards to p-values: the p-value tells us P(data|null hypothesis), but the quantity we actually want to know is P(null hypothesis|data). These are not the same!
Let's say you want to test the hypothesis that wearing a green hat makes any die you roll get its max result. You put on a green hat and roll a d20, and it comes up 20. If the null hypothesis were true (the null hypothesis being "the hat has no effect on the die"), the chance of getting such a good roll would be only 1/20, or 5%. So the p-value of this experiment is 0.05.
Does this mean you can conclude that the null hypothesis has only a 5% chance of being true, and it's 95% likely that wearing a green hat does affect die rolls? Of course not! We have centuries of investigation by mathematicians, physicists, and superstitious D&D players into how dice work, and we can be extremely confident that the color of hat you're wearing has no measurable influence on the result. P(data|null hypothesis) in this case is 0.05, but P(null hypothesis|data) is more like 0.9999999.
Confusion abounds
False statements like "the p-value is the chance that the null hypothesis is true" are extremely common in casual and professional teaching resources alike.
Even when a resource manages to avoid saying that explicitly, that assumption often sneaks in elsewhere. You'll see stuff like "if the p-value is low, you can be confident that the effect you're testing for probably exists", or "the p-value is a way of quantifying how confident we should be that the null hypothesis is false". These are all the exact same error, just stated in different words.
Why does it happen so frequently? Well, because that's what we intuitively want from a study. When we perform an experiment, the purpose is to figure out whether some effect exists, with the idea being that we gather data and check if the data supports the hypothesis. So what we want to find out is P(hypothesis|data), but what p-values actually tell us is P(data|hypothesis), which could be wildly different.
Indeed, even the traditional terminology of "rejecting the null hypothesis" is highly misleading. If you ask a statistician, they'll tell you that "rejecting the null hypothesis" is just a synonym for "p was less than 0.05". But in normal English, "rejecting" a statement kind of implies that you don't think it's true. As we saw with the green hat example, it does not work this way; you could run an experiment rolling a few dice, "reject the null hypothesis", and still justifiability be extremely confident that wearing a green hat had no effect on the dice you rolled.
This is the cause of all of the confusion I mentioned in the first paragraph. p-values are what the entire field of null hypothesis significance testing is built upon
So why do we use them?
In the D&D video above, the players roll sixteen 1s in a row, equivalent to a p-value of ~0.0000000000000000000015. In such a situation, should we still conclude that the dice are fair? No. That's such an unlikely occurrence that we should clearly start to think something else is going on.
We don't always need such a low p-value in order to draw a conclusion about the probability of the null hypothesis. Maybe you want to investigate whether ants like peanut butter. Ants don't eat most substances, so you start with the null hypothesis that ants don't care about peanut butter. You run a test that counts the number of ants that go towards different things, and find that they spend a lot more time near the peanut butter than near a rock, with a p-value of 0.04. Here we can reasonably conclude that ants do like peanut butter even without a particularly low p-value.
The difference has to do with our existing beliefs about the situation. We already know that dice are not affected by a green hat, so a huge amount of evidence is needed to overcome that. Whereas ants liking peanut butter is very plausible given what we already know about ants, so much less evidence is needed in order to conclude that it's probably true.
So a p-value alone does not tell us the chance that the null hypothesis is true, but when combined with our prior beliefs about the world, it can. This is formalized in Bayes' Theorem: P(H|E) = (P(H) * P(E|H)) / ((P(H) * P(E|H)) + ((1 - P(H)) * P(E|¬H))).
That is, we start with our prior belief about how likely it is that ants don't like peanut butter, before looking at any of our experimental data. Let's say it's 50%, since we know that ants like some human food, but not all of it, and we have no idea how they'll feel about peanut butter. That's P(H). (Remember that we're testing the null hypothesis here, not the alternative hypothesis.) P(E|H) is our p-value, the chance of observing evidence at least this strong given that the null hypothesis is true, which our experiment determined is 0.04.
Doing this in the die rolling example gives us a different result. Our prior belief that green hats do not influence die rolls is 0.9999999, we think that if green hats do influence die rolls there's a 99% chance the die will come up 20 while we're wearing the hat, and we performed the experiment and got a p-value of 0.05. Using Bayes' theorem, we get out a posterior probability of 0.99999802 for the null hypothesis. Seeing the die come up 20 while wearing a green hat has slightly decreased our confidence that the die is fair, but not by much.
So p-values are useful! But only with the context of our existing knowledge about the world.
Practical significance
So the p-value on its own does not tell you the chance that the paper is wrong. However, it can be used to derive the false positive rate. Traditional statistical significance testing has you choose a specific number, called alpha, and if your p-value is less than or equal to alpha, you "reject the null hypothesis" and can publish your paper. Alpha is usually set to 0.05. This means that, if we assume no experimental error, out of 100 papers investigating a true null hypothesis, we'd expect 5 (on average) to get a p-value of 0.05 or below and incorrectly reject the null hypothesis.
(For studies where the null hypothesis is true, the p-value varies randomly.
But knowing that the false positive rate is only 5% can be deceptive. The false positive rate is not the chance that a given study is wrong due to having a false positive, nor is it the chance that a study that found a positive result is wrong.
I've created a simple demonstration of this. In addition to choosing the p-value threshold (alpha), you'll also need to choose the average study statistical power, which is how well the study would successfully detect an effect that does exist. And you'll need to pick the overall prevalence of studies that are investigating an effect that actually exists. Those three factors determine the outcome of any study performed."
(Note how these correspond exactly to the inputs of Bayes' Theorem. The alpha is a threshold on the p-value, P(E|H), the statistical power is a threshold on the q-value, P(E|¬H), and the prevalence is the prior, P(H).)
Once you've chosen those three factors for a scientific field, the colored area on the right shows a breakdown of what all the studies would be like in that field. You can think of each pixel as a single study, so the area of a certain color is proportional to the fraction of studies in the field that had that result.
Alpha:
Average statistical power:
Prevalence:
: True positives. ()
: False positives. ()
: False negatives. ()
: True negatives. ()
+ : Chance that a study comes up positive. ()
+ : Chance that a study is correct. ()
/ ( + ): Chance that a positive study is correct. ()
Consider a realistic example from psychology. Set the alpha level to 5% and the statistical power to 80%, which are the traditional target values for each. Psychology tends to investigate some... questionable ideas, so let's say that 10% of studies are investigating a real effect.
We see that 93.5% of studies will be correct, which seems pretty good at first glance. But the vast majority of those correct results are true negatives, and any study that found no effect likely won't be published. If we look only at the positive studies, the ones that you'll actually see in scientific journals, a full 36% of them are wrong! That's not great.
This is what's going on in the classic XKCD comic:

The p-value is working exactly as intended here. They performed 20 studies, got 19 true negatives and 1 false positive for a false positive rate of 5%, as expected. But only the positive one is exciting enough to get published or mentioned in the news, so the wrong result ends up being much more impactful than the correct ones.
It gets worse. 80% statistical power may be recommended, but it's usually not reached. Estimates of the actual power in most studies range from less than 50% in psychology and around 20% in neuroscience, to 7% in economics, to less than 6% across the board by some of the more cynical statisticians.
And a p-value of <0.05 is also optimistic. Recall that the p-value is conditional on no experimental error. But when a low p-value makes it easier to publish and gain prestige in the scientific field, there's a lot of incentive for convenient errors. (Note that under the above assumptions, the chance of a paper coming up with a positive result is only 12.5%, meaning researchers are going to have to throw out 7 out of every 8 studies they perform for being nonsignificant. Do you really think they're doing that?
If you change the simulation above to use more realistic values of alpha = 10% and power = 20%, now more than 80% of published studies are wrong. And indeed, the fact that most published research is false is well-accepted.
As you can see in the simulation, a low p-value does have a positive effect; the lower you set the alpha, the more reliable the results are. This paper tested this in practice by attempting to replicate 100 published psychology papers, and found that those published with a p-value from 0.04 to 0.06 replicated only 18% of the time, whereas those with p < 0.02 replicated 41% of the time, and p < 0.001 replicated 63% of the time.
So a low p-value threshold does help improve study accuracy. But... not by that much. In any realistic field of science, a paper with p = X will have a much greater than X chance of being wrong, and you have to take other factors into account in order to correctly derive the practical implications of the study. And if the p-value seems too good to be true... it probably is.
In 2011, CERN announced they had discovered faster-than-light neutrinos with a p-value of 0.0000000002823. This would be strong evidence against general relativity if the study was performed as described, but there turned out to be a loose wire in their setup, rendering this p-value completely invalid.
Update: we have a new winner. P = 4.4 * 10^-25121 🤯
— Dmitry Kobak (@hippopedoid) June 28, 2023
From https://t.co/xZsYFxQDi3. Found by @CasualVariant. [4/3] pic.twitter.com/pChLhSLAyG
Are they "evidence"?
A p-value may not be the chance that the null hypothesis is true, but a low p-value still indicates that the null hypothesis is less likely than it would have been if you had gotten a higher p-value, right? So a p-value is a measure of evidence against the null hypothesis, and the lower the p-value is, the more evidence you have against it?
Not exactly. Consider spinning a wheel, and you want to determine if there's a bias in how it will stop. Your null hypothesis is that there's no bias, and your alternative hypothesis is that it is biased towards some area. The only data you have access to is to define a region on the wheel centered where you think the bias might be, and know whether the wheel stopped within that region.
So you start by designating a region equal to 1/100 of the wheel, and it stops inside that region. Your p-value is therefore 0.01. But the amount of evidence that this p-value provides depends on what the proposed bias is! If the bias is narrow, being extremely likely to stop within that region, then this is pretty compelling; it's much more likely that the wheel is biased than that you just got lucky with an unbiased wheel.
But if the bias is broad, causing the wheel to be only slightly more likely to end in that region, then this is quite a coincidence either way. You'd need a lot more spins to begin to get an idea of which hypothesis is more likely.
So a p-value of 0.01 clearly doesn't stand for any constant amount of evidence. Rather what provides the evidence is the ratio between the p-value and the chance of getting data at least this extreme conditional on the null hypothesis being false. This quantity doesn't have a name in traditional statistics, so I'll call it the q-value.
(The q-value is related to the p-value in almost the same way that statistical power is related to alpha, just inverted. Alpha determines the false positive rate, and is an arbitrary threshold that the researcher sets in order to classify possible p-values into two buckets of rejecting or not rejecting the null hypothesis. Statistical power is the true positive rate, and could be used as an arbitrary threshold to accept the alternative hypothesis if the q-value falls above it. In practice people generally frame everything in terms of the p-value instead of the q-value, but both framings are functionally equivalent.)
This makes intuitive sense. We're trying to distinguish between possible worlds, so we need to know which world would be more likely to generate the evidence that we've seen. If one of those worlds is much more likely to give us that evidence, then we're probably living in that world. But if the evidence we've observed is largely unrelated to the difference between those possible worlds, and then it doesn't give us much information either way.
We can see this ratio in Bayes' theorem:
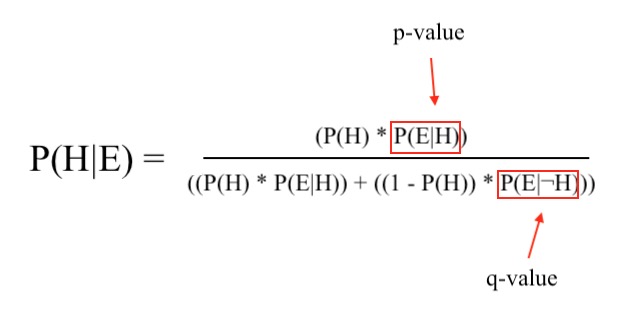
So the p-value on its own is not enough to be useful. We also have to know the q-value, and it's the ratio of the two (combined with our prior) that tells us how much we should believe in the null or alternative hypothesis. If the p-value is smaller than the q-value, this is evidence towards the alternative hypothesis. If the q-value is smaller, that's evidence towards the null hypothesis. This is known as the likelihood ratio or Bayes Factor, and it is a measure of evidence.
Now it is true that, if you hold the q-value constant, decreasing the p-value decreases the probability of the null hypothesis. So you could say "all else being equal, a lower p-value is more evidence against the null hypothesis". But the problem with that is that most of the study parameters that are easy to tweak will end up changing not only the p-value but also the q-value. (e.g. making the size of the test area on the spinning wheel smaller makes the p-value smaller, but also makes the q-value smaller.)
Calculating p-values
Ok, enough about the theory. How do scientists actually arrive at their numbers?
First you have to define a clearly-specified null hypothesis. This is usually pretty straightforward, but not always.
Imagine you've developed a new drug called Tybuprofen, and you want to see whether it works as a painkiller. So you gather 100 people experiencing pain, ask them to rate it on a 0-10 scale, give them Tybuprofen, ask them to rate their pain on the same scale again an hour later, and calculate the p-value of the difference. It's 0.001. You can publish!
Then you hear about something called "regression to the mean" and decide to run another study with a control group. You divide your pain-experiencing subjects into two groups at random, one group takes Tybuprofen, the other takes nothing, and you ask them both to rate their pain on the scale. Checking the p-value of the difference, it's 0.02. You can still publish, nice.
But before you can do so, an annoying colleague points out something called the "placebo effect". So you run a third study, this time giving the control group a sugar pill that looks and tastes the same. p = 0.05. Well, it's on the edge of significance, should be fine.
Hmm, but was that the best dosage? Maybe a higher dose would do a better job? You once again gather some people in pain, giving one group 400mg and the other 800mg. Checking the p-value of the resulting ratings, it's 0.11, not significant. Ah well.
You have now run four studies with four different null hypotheses.
- Null hypothesis #1: People on Tybuprofen will experience no reduction in pain.
- Null hypothesis #2: People on Tybuprofen will experience the same reduction in pain as people not on any drug.
- Null hypothesis #3: People on Tybuprofen will experience the same reduction in pain as people on a sugar pill.
- Null hypothesis #4: People on 800mg of Tybuprofen will experience the same reduction in pain as people on 400mg of Tybuprofen.
Each of them was a reasonable choice. But who chooses what counts as "reasonable"? After all, if you were trying to test for the existence of the placebo effect, you'd want to use #2, but if trying to test for a painkiller effect of Tybuprofen in particular, #3 is more fitting. It's context-dependent! And we only want to use null hypothesis #3 because we think the placebo effect exists. We don't feel a need to ensure that our control group is standing at the exact same longitude as the test group, because our model of the world tells us that it's very unlikely for this to have an effect.
Consistently-used null hypotheses, like "people taking the drug report the same outcomes as people on a sugar pill" help cut down on inconsistency when applied across the entire scientific industry. They make sure everyone is on the same page with regards to what, exactly, the p-value is comparing a study's results to. But the choice of null hypothesis that we use to calculate the p-value is somewhat subjective. We try to pick one that is conceptually as "simple" or "boring" as possible, one that doesn't make any assumptions about the world, but we have to be careful, and be clear what we mean when we talk about the null hypothesis.
Ok, now imagine you have a coin that may be biased towards heads or tails. you don't know, but you want to find out. So you flip it 100 times, and get 60 heads. Using the null hypothesis of it being a fair coin, you use a binomial distribution calculator to check the chance of getting ≥60 heads under the null hypothesis that the coin is fair, and get 0.028. So that's our p-value, right?
But wait! That's the chance of getting at least that many heads. What about tails? The coin could have been biased towards tails too. Taking that into account doubles the p-value to ~0.056.
So it matters what hypothesis we're testing, since that determines what "at least as confirmatory" actually means. If the hypothesis is "it's biased towards heads", we only want to check how extreme the results were in the direction of heads. But if the hypothesis is just "it's biased in some way", you'd want to check both directions.
These are known as one-tailed and two-tailed tests, respectively. Consider how likely each number of heads is under the null hypothesis. 50 is the most likely number, then 49 and 51 are next most likely, etc. If you plot these out, you get a binomial distribution.
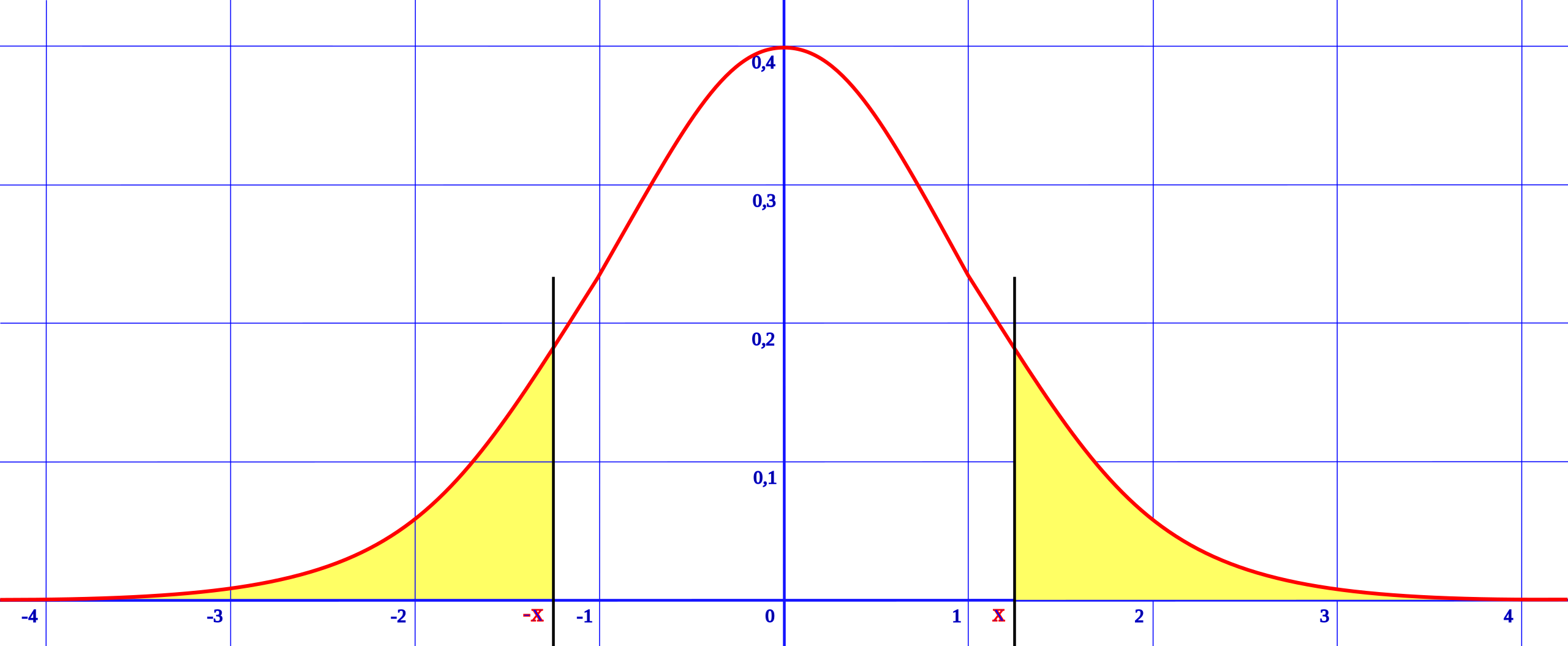
But hold on a minute. "Biased towards heads" isn't a single theory; how biased are we talking?. A coin could be highly biased, getting 90% heads. Or it could be only slightly biased, getting 55% heads. If our p-value is supposed to take into account the alternative hypothesis as well as the null hypothesis, shouldn't we get a different value depending on which specific level of bias is hypothesized? Getting 60 heads out of 100 flips is pretty likely under the theory that the coin is 55% biased towards heads, but very unlikely if it's 90% biased.
And what about more complicated patterns? If you flip the coin 100 times and get 50 heads in a row followed by 50 tails in a row, that doesn't seem very random, but any method of calculating a p-value that relies on only the number of heads (and not their order) will return a high p-value.
There are many different ways to deal with this problem, and this is another source of subjectivity. Different statistical tests are available for different kinds of hypothesis; one and two tailed tests, Student's t-tests, F-tests, chi-squared tests, one-way ANOVA, etc. The experimenter has to choose which one makes the most sense for their particular hypothesis.
Most significance tests rely on collapsing the data down to a single number, called a "test statistic", and then comparing that number to the distribution of numbers you would expect to get under the null hypothesis. In our first coin flip example, the total number of heads was the test statistic, and the p-value is a measure of how far away from the mean of the binomial distribution it lies.
This is why I said at the beginning that the p-value is more of an approximation. When a scientist comes up with a hypothesis like "Tybuprofen reduces pain", that really stands for an infinite class of hypotheses that each have it reduce pain by a different amount. The scientist picks some formalization of this hypothesis that puts a specific probability distribution over the outcomes, then picks some way to compare that distribution to the null hypothesis distribution, and reports that as the p-value. (Or in simple cases like the coin flip example, they just look at the distance from the mean of the null hypothesis, without needing a specific alternative distribution.) So different reported p-values are testing subtly different things, depending on the particular test used.
Quiz
To help make sure you've understood everything correctly, I've taken some quotes about p-values from various well known sources. Try to grade them as right or wrong.
#1. From Choosing and Using Statistics: A Biologist's Guide (second edition), a textbook from 2009, written by a professor of biology at the University of York:
"The P-value is the bottom line of most statistical tests. It is simply the probability that the hypothesis being tested is true. So if a P-value is given as 0.06, that indicates that the hypothesis has a 6% chance of being true. In biology it is usual to take a value of 0.05 or 5% as the critical level for the rejection of a hypothesis. This means that providing a hypothesis has a less than one in 20 chance of being true, we reject it. As it is the null hypothesis that is nearly always being tested we are always looking for low P-values to reject this hypothesis and accept the more interesting alternative hypothesis."
Is this statement correct?
No. The p-value is not the chance that the null hypothesis is true. (See the section on conditional probability above for where I cover that.)
#2. From Choosing and Using Statistics: A Biologist's Guide (third edition), the same textbook from 2011:
"The P-value is the bottom line of most statistical tests. It is the probability of seeing data this extreme or more extreme if the null hypothesis is true. So if a P-value is given as 0.06 it indicates that you have a 6% chance of seeing data like this if the null hypothesis is true. In biology it is usual to take a value of 0.05 or 5% as the critical level for the rejection of a hypothesis. This means that providing a hypothesis has a less than one in 20 chance of being true we reject it. As it is the null hypothesis that is nearly always being tested we are always looking for low P-values to reject this hypothesis and accept the more interesting alternative hypothesis."
Is this statement correct?
No. They fixed the incorrect definition in the 2nd and 3rd sentences, but did not fix the exact same incorrect claim in the 5th sentence: "This means that providing a hypothesis has a less than one in 20 chance of being true we reject it." A test of statistical significance does not tell you the hypothesis's chance of being true.
And the same error continues to occur across the rest of the textbook's third edition. For example, several chapters later, it says "What a statistical test determines is the probability that the null hypothesis is true (called the P-value)."
#3. From Stevenson, 2024; a review of methodological errors in criminology research and how the replication crisis has affected the field:
"With standard hypothesis testing methods, there will be one false claim of a relationship between a cause and purported effect for every nineteen times that it fails to find support"
Is this statement correct?
No. This quote forgets to condition on the null hypothesis. In other words, it claims that alpha provides the rate "false positives / (false positives + all negatives)", when in reality it provides the rate "false positives / (false positives + true negatives)".
#4. From Davis & Mukamal, 2006; a statistical primer for cardiovascular research:
"For hypothesis testing, the investigator sets the burden by selecting the level of significance for the test, which is the probability of rejecting the null hypothesis when the null hypothesis is true."
Is this statement correct?
Ambiguous phrasing.
The most natural interpretation is "p(rejecting the null hypothesis when the null hypothesis is true)", in which case it's false. This quantity is "false positives / all results", which is not solely determined by alpha, and is guaranteed to be lower.
But there's also the reasonable interpretation of "p(rejecting the null hypothesis) when the null hypothesis is true", or equivalently "the probability of rejecting the null hypothesis in the world where the null hypothesis is true". This is p(rejecting the null hypothesis | the null hypothesis is true), which is indeed the correct definition of alpha.
#5. From the Towards Data Science blog with several hundred thousand readers, written by Cassie Kozyrkov, former chief decision scientist at Google:
"All of hypothesis testing is all about asking: does our evidence make the null hypothesis look ridiculous? Rejecting the null hypothesis means we learned something and we should change our minds. Not rejecting the null means we learned nothing interesting, just like going for a hike in the woods and seeing no humans doesn’t prove that there are no humans on the planet. It just means we didn’t learn anything interesting about humans existing."
Is this statement correct?
No. "Rejecting the null hypothesis" just means "p was less than alpha". (Usually 0.05.) As discussed above, it's often not correct to change your mind and start believing that the null hypothesis is false just from a single study that found p < 0.05.
This is an example of what I was alluding to in footnote #3. I suspect that this author has heard "the p-value is not the probability that the null hypothesis is true" before, and so avoided saying anything like that explicitly. But they don't seem to actually understand what the p-value is, and still intuitively feel like the p-value is the chance that the null is true. So they use vague and suggestive terminology like "makes the null hypothesis look ridiculous" as a way to imply something like "a low p-value disproves the null", without saying so outright.
This quote also makes a second, unrelated error: In the context in which a low p-value is evidence against the null hypothesis (that is, when the statistical power of the test is held constant), having a high p-value is indeed evidence in favor of the null hypothesis, because a high p-value is more likely to occur if the null hypothesis is true than if it is false. It's not necessarily very strong evidence, but the law of conservation of expected evidence requires it to be nonzero. If you walk in the woods and see no humans, that is weak evidence towards there being no humans on the planet, and the more of the planet you explore while still seeing no humans, the stronger and stronger the evidence becomes.
#6. From a speech at the Royal Statistical Society by Sir David Cox, winner of the 2017 International Prize in Statistics:
"If we found a p-value of 7%, it would say 'if we were to take these data as just decisive against the null hypothesis, then in 7% of the cases in the long run in which the hypothesis is true, it will get rejected falsely'."
Is this statement correct?
Yes. Out of only the cases where the null hypothesis is true, if you always reject the null hypothesis with a p-value of 7% or less, then 7% of the studies will reject it falsely. (Since the chance of getting a p-value of 7% or less is... 7%, and you falsely reject the null every time that happens.) This is just another way of describing the false positive rate.
#7. From ChatGPT when I asked it what a p-value is:
"A p-value quantifies the strength of evidence against the null hypothesis. By comparing the p-value to a predetermined significance level (usually 0.05), researchers can assess the likelihood that their observed data would occur if the null hypothesis were correct. A small p-value suggests that such data are unlikely, indicating strong evidence against the null hypothesis."
Is this statement correct?
No. In order to know the strength of the evidence against the null hypothesis, you need to know not only the p-value, but also the chance of having gotten data at least that extreme conditional on the null hypothesis being false. (I called this the "q-value" above.) It's the ratio between those two quantities that determines the strength of the evidence. A low p-value could in fact be evidence in favor of the null hypothesis if the q-value is even lower.
It also seems to be making the mistake of thinking that the p-value tells you the chance of getting exactly your data, when in reality it's the chance of getting any data at least as extreme as the data you got. Those two quantities are very different, and the chance of getting exactly your data will always be much lower. (Just like how if you flip 100 fair coins, the chance of getting at least 55 heads is about 18%, but the chance of getting exactly 55 heads is less than 5%.)
#8. From Elementary Statistics in Social Research, a textbook by James Alan Fox and Jack Levin, both well-known criminologists who frequently consult for the white house and in criminal trials:
"The difference between P and a can be a bit confusing. To avoid confusion, let’s compare the two quantities directly. Put simply, P is the exact probability that the null hypothesis is true in light of the sample data; the a value is the threshold below which is considered so small that we decide to reject the null hypothesis. That is, we reject the null hypothesis if the P value is less than the a value and otherwise retain it."
Is this statement correct?
No, same error as the previous textbook. The p-value is still not the chance that the null hypothesis is true, it has never been that, and it will never be that.
I'm including this example to really drive home how unreliable many statistics resources are, even when written by well-credentialed "experts". These authors later copied this entire paragraph word-for-word into a second textbook, Elementary Statistics in Criminal Justice Research.
#9. From the Simple English Wikipedia's February 2021 page on misuse of p-values:
"In statistics, a p-value is the probability that the null hypothesis (the idea that a theory being tested is false) gives for a specific experimental result to happen. p-value is also called probability value. If the p-value is low, the null hypothesis is unlikely, and the experiment has statistical significance as evidence for a different theory."
Is this statement correct?
No. The first sentence is fine, but "If the p-value is low, the null hypothesis is unlikely" is false. As previously mentioned, rolling a d20 and getting a 20 gives you a p-value of 0.05, but that doesn't mean you should conclude the die is likely unfair.
#10. From Kareem Carr, Twitter statistician:
"THE LOGIC OF THE P-VALUE. Assume my theory is false. The probability of getting extreme results should be very small but I got an extreme result in my experiment. Therefore, I conclude that this is strong evidence that my theory is true. That's the logic of the p-value."
Is this statement correct?
No, p-values do not quantify evidence. If the q-value is equally low, a low p-value is not evidence either way.
#11. From a well-known review of common p-value misinterpretations, with over 1500 citations:
"Any P value less than 1 implies that the null hypothesis is not the hypothesis most compatible with the data, because any other hypothesis with a larger P value would be even more compatible with the data."
Is this statement correct?
Yes, there's always some hypothesis that would perfectly predict the data you observed. For example if you flip a coin 10 times and get 6 heads, this has only a ~20% chance of happening under the null hypothesis, but you could have another hypothesis that says "coins keep track of their previous flips and always stick as closely as possible to a 60% ratio", and that hypothesis would assign 100% probability to the result you saw.
However if, as in most studies, you're only considering two possible hypotheses, then a p-value less than 1 can provide evidence in favor of the null hypothesis, if the q-value is smaller.
#12. From the Firebase A/B test documentation:
"P-value, which represents the probability that there is no true difference between the variant and baseline; in other words, any observed difference is likely due to random chance. The lower the p-value, the higher the confidence that the observed performance remains true in the future."
Is this statement correct?
No. There being "no true difference between the variant and baseline" is equivalent to the null hypothesis being true, which as we've already seen, is not what the p-value is the probability of.
#13. From Sabine Hossenfelder, a theoretical physicist and philosopher of science, and one of Youtube's most popular science educators:
"Their result was incompatible with prediction at 6.8 sigma, which would be a less than one in a trillion chance of it being just random noise."
Is this statement correct?
No.
Some background: "Sigma" is how physicists refer to a p-value; 1 sigma is one standard deviation away from the mean. Physicists have higher standards than the rest of science, so they generally use a threshold of 5 sigma, which corresponds to a p-value of ~0.0000003 if it's a one-tailed test, or ~0.0000006 if it's a two-tailed test.
(The field of manufacturing also uses sigma values to measure their rate of defects and they frequently claim to target 6 sigma, but they do weird math so that it's actually more like 4.5.)
Anyway, Sabine claims that the p-value being less than 1 in a trillion means that the probability of the observations being random noise is less than 1 in a trillion. But "the observations are just noise" is another way of saying "there is no real effect here", which means "the null hypothesis is true". Bad Sabine.
#14. From the official CERN webpage, explaining the statistical background behind the discovery of the Higgs Boson:
"For some results, whose anomalies could lie in either direction above or below the expected value, a significance of five sigma is the 0.00006% chance the data is fluctuation. For other results, like the Higgs boson discovery, a five-sigma significance is the 0.00003% likelihood of a statistical fluctuation, as scientists look for data that exceeds the five-sigma value on one half of the normal distribution graph."
Is this statement correct?
No. This paragraph is trying to explain the difference between one and two tailed tests, but makes the same error as Sabine, claiming that the statistical significance is the chance that their conclusions are mistaken.
They make the same error in part 3 of their video series on the subject, saying "The commonly accepted threshold for discovery is the point at which the probability that there's nothing there, and that the peak we're seeing is just the result of pure chance, the probability of that is about 1 in 3.5 million."
#15. From Thinking in Bets, a book about uncertainty and probabilistic thinking, by Annie Duke, a professional poker player and business coach:
"When scientists publish results of experiments, they share with the rest of their community their methods of gathering and analyzing the data, the data itself, and their confidence in that data. That makes it possible for others to assess the quality of the information being presented, systematized through peer review before publication. Confidence in the results is expressed through both p-values, the probability one would expect to get the result that was actually observed (akin to declaring your confidence on a scale of zero to ten), and confidence intervals (akin to declaring ranges of plausible alternatives)."
Is this statement correct?
No. The "probability one would expect to get the result that was actually observed" is the Bayesian prior on the data. It's not conditional on the null hypothesis, and thus will always be higher than the p-value, since it accounts for the chance that the experimental hypothesis is true.
With thanks to VesselOfSpirit, detectiveenters, and Tom Kealy for feedback and suggestions. Any errors are my own.